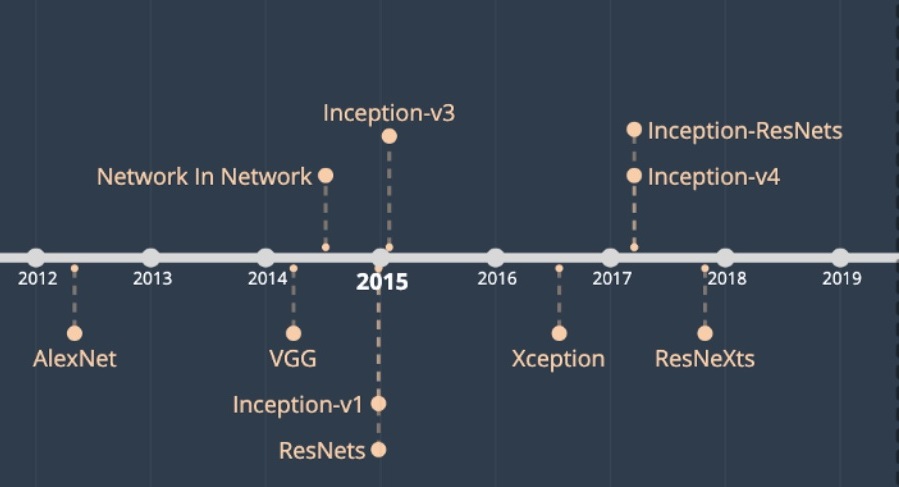
El diagrama de Alfred H. Barr es un dispositivo de naturaleza visual basado en una lógica ordenadora espacial; dicho de otro modo, la decodificación e interpretación de sus potenciales significados deviene de una determinada disposición de los elementos en el plano bidimensional, además de aspectos relacionados con su configuración gráfica y ortotipográfica. Es significativo, por ejemplo, que la lectura de arriba-abajo a la que propende el diseño del propio diagrama, con sus líneas de tiempo cronológicas enmarcando el espacio por lateralmente por ambos lados, la dirección de las puntas de flecha y el propio formato rectangular hayan sido clave para su interpretación prevalente en términos genealógicos, pese a que el diagrama de Barr es mucho más que una genealogía, al incluir todo un conjunto de relaciones transversales que conectan entre sí los diferentes movimientos, poéticas y autores que incluye.
La exposición Genealogías del Arte (2020), que inspira el experimento Barr X Inception CNN, indaga justamente en estas relaciones transversales del diagrama de Barr, pese a que su título incida en la cuestión genealógica. Así, en un ejercicio arriesgado de gran creatividad, la instalación museográfica transforma el esquema diagramático bidimensional en un espacio tridimensional, físico, modelado por las relaciones visuales que establecen entre sí las obras materialmente presentes.
De este modo, la abstracción diagramática de Barr, con su función indexical, se corporeiza en un artefacto tridimensional que conlleva una espacialidad distinta a la del plano bidimensional; una espacialidad en la que se hacen visualmente presentes las conexiones visivo-formales prefiguradas en el diagrama, además de dar ocasión a la emergencia de otros planos de relación no prefigurados por Barr pero que la coaparición de imágenes en un mismo espacio hace posible, como muy bien sabía Aby Warburg (1866-1929).
El espacio de Genealogías del Arte es aquel que puede ser recorrido y experimentado físicamente por el visitante (no solo visualmente), en un proceso a través del cual el espacio físico euclídeo se convierte en una duración[1]; un espacio que se despliega a medida que transcurre el recorrido, a medida que transitamos de una sala a otra; en definitiva, pareciera que estuviésemos en una versión tridimensional de los paneles de Warburg donde los intervalos o espacios intersticiales entre imágenes se han transformado definitivamente en espacio-tiempo.
El proyecto Barr X Inception CNN ha querido contribuir a estas lecturas espaciales proponiendo otro tipo de espacialidad.
Entre las profundas transformaciones que han dado lugar a nuestra actual sociedad tecnomediada, quizás la que más afecte a la propia configuración del campo del arte sea la metamorfosis que la dimensión ontológica de los objetos culturales viene experimentando desde hace ya algunas centurias. Si el siglo XX culminó, gracias a los avances de la fotografía y de los instrumentos de reproducción mecánica, el proceso iniciado por los medios gráficos en cuyo transcurso los artefactos culturales quedaron mutados en sus respectivas reproducciones visuales, la generalización de la tecnología digital en el siglo XXI ha traído consigo la transformación de estas reproducciones en una masa de información en forma de bits y píxeles, es decir, valores numéricos susceptibles de ser computados matemáticamente.
Este cambio ontológico es de amplio alcance, pues supone, en primer lugar, que las características visivo-formales que identificamos como propias de las imágenes digitales no son otra cosa que datos numéricos que se reconstituyen ante nuestra mirada en una pantalla. Es importante enfatizar esta cuestión porque la reconstitución de la imagen en el dispositivo digital suele generar la ilusión óptica de que estamos tratando con imágenes en cuanto entidades icónicas, cuando en realidad estamos tratando con ítems de información numérica. En segundo lugar, y como consecuencia de lo anterior, esta transformación ontológica también supone que el análisis –y ordenación- de los objetos culturales devenidos en reproducciones digitales pasa a ser un problema de orden matemático. Desde un punto de vista computacional, la imagen digital no es más que una superficie de información numérica de la que se pueden extraer características informativas también de naturaleza numérica.
En este escenario operan las redes neuronales artificiales, arquitecturas computacionales vinculadas a la Inteligencia Artificial (IA). En particular, las redes neuronales convolucionales (CNN por sus siglas en inglés) son dispositivos de visión por computadora entrenados para detectar similitudes formales entre imágenes digitales transformadas en vectores de información numérica. Su proyección en el espacio bidimensional, que en este proyecto hemos denominado «campo visual», responde a estos criterios de contigüidad, de modo que la mayor o menor proximidad entre las imágenes ha de interpretarse como un indicativo de su mayor o menor similitud visivo-formal. ¿Pero de qué está hecho este campo visual? ¿Cuál es su naturaleza?
A simple vista, el resultado del actuar maquínico da como resultado un dispositivo de naturaleza visual, que pone en funcionamiento una concepción relacional de las imágenes, las cuales se distribuyen en el espacio según una determinada morfología. Así las cosas, este tipo de dispositivo visual debería –y debe- ser ubicado en una continuidad material e histórica respecto de otros dispositivos que a lo largo del tiempo han ido configurando el modo como miramos los objetos culturales y, por tanto, los interpretamos en su dimensión icónico-iconográfica. Es imposible no traer a la mente el Atlas Mnemosyne (1926-1929) de Aby Warburg, fruto también de una concepción relacional de las imágenes[2]. Hay, sin embargo, diferencias sustantivas que nos permiten hablar de un nuevo tipo de espacialidad.
Barr X Inception CNN nos confronta con el quehacer de tecnologías de visión por computadora no supervisadas, esto es, tecnologías en las que la clasificación, categorización u ordenación de las imágenes son llevadas a cabo por procesos estrictamente computacionales sin intervención directa del sujeto humano y, por tanto, con independencia de las categorías epistemológicas que configuran el conocimiento disciplinar de la Historia del Arte. Dado que la visión por computadora es cálculo de información numérica, es la lógica matemática la que se encuentra en la base de la posible producción de significado: dicho con otras palabras, es la mayor o menor similitud entre los datos numéricos lo que se instituye en el principio ordenador, aproximando o alejando las imágenes digitales –transformadas, no lo olvidemos, en vectores de información numérica- en un espacio métrico vectorial.
En consecuencia –y esto resulta muy evidente-, en el espacio producido por una Inception CNN la función cognitivo-psíquica del sujeto es sustituida por el cálculo y el cómputo. La lógica matemática sustituye, así, a la acción perceptiva como acto cognitivo, a la acción del pensar como conexión y asociación semántica de ideas, y a la acción psíquica de la memoria, consciente o inconsciente. Las conexiones visuales y semánticas basadas en la facultad perceptivo-cognitiva y en la acción de la memoria son reemplazadas por el cómputo matemático de características visivo-formales traducidas a datos numéricos.
Por tanto, y a diferencia de las configuraciones diagramáticas que se han sucedido a lo largo de la Historia del Arte, la configuración morfológica que ahora nos ocupa no representa una idea preexistente en una mente humana, un pensamiento formulado ni un relato previamente articulado; no se trata de la construcción de un argumento visual para contar algo, o a través del cual se nos revele un estado psíquico, consciente o inconsciente. Por el contrario, se trata nada más –pero nada menos- de un hacer computacional traducido en formas a-ideáticas o a-psíquicas, si es que podemos utilizar estos términos para describir estas conformaciones visuales que no representan ni vehiculan ideas, pensamientos o historias que hayan habitado previamente una mente humana; ni son el resultado de determinados estados mentales. Las configuraciones formales resultado del procesamiento computacional non son, por tanto, formas representacionales; sino formas en las que se revela el hacer maquínico y que responden a su rationale.
Llegados a este punto, el concepto de knowledge generator formulado por Johanna Drucker [3] nos puede servir para explicar estas configuraciones en su condición de formas generativas, es decir, formas generadas por un dispositivo maquínico con una rationale distinta a la del sujeto humano pero que operan –por eso mismo- como espacios no «de» sino «para» la producción de conocimiento; configuraciones formales, por tanto, que instan al descubrimiento de lo que los datos visuales matemáticamente computados nos cuentan, que deberá ser hilado, posteriormente, en una historia, narrativa o relato que lo dote de sentido. Formas que invitan a la exploración creativa más que a una lectura decodificadora; en definitiva, formas visuales necesitadas de una interpretación que no emana de la tarea hermenéutica -pues no hay ideas subyacentes que discernir-, sino de un ejercicio de heurística creadora. Así es como estas configuraciones formales se hacen significativas para el sujeto humano, y así es como se instituyen en espacios de negociación entre el decir cuantitativo y el concebir cualitativo. Es por eso que, a mi entender, estos dispositivos visuales generativos constituyen nuestro espacio intersticial entre la máquina y el sujeto. Este espacio de naturaleza computacional, hecho de información procesada matemáticamente, actúa como interfaz entre la rationale de la máquina y la del ser humano; el medio en el que el hacer maquínico se hace inteligible para el sujeto mediante un proceso de dotación de sentido.
En cuanto espacio vectorial, el campo visual producido por una Inception CNN es, en realidad, un campo de fuerzas conformado por imágenes que, en su condición de vectores de información numérica, actúan como líneas de fuerza con una dirección y una intensidad determinadas. La conformación visual que se despliega ante nosotros en el espacio vectorial expresa, por tanto, un «estado» dado, la resultante de la tensión establecida entre las imágenes-vectores-fuerzas cuando alcanzan un punto de equilibrio. La constelación o campo visual es, pues, la resultante de todas las fuerzas actuando al mismo tiempo, pronto a desestabilizarse y/o reconfigurarse en cuanto una imagen-vector-fuerza se desplaza o nuevos vectores-fuerzas se incorporan. La imagen, como punto en un espacio, no es solo ella, es también el conjunto de fuerzas en el que se inscribe. El estado de equilibrio es una permanencia, en consecuencia, transitoria; el estado entre una multiplicidad de desplazamientos y reconfiguraciones posibles. El campo visual es, así, intrínsecamente dinámico.
El espacio vectorial también materializa la estructura y morfología que emana de un espacio construido a partir de conexiones y contigüidades entre objetos culturales de naturaleza visivo-formal. Lo que se hace visible es la forma y estructura que subyace a los datos, poniendo de manifiesto continuidades y discontinuidades, conexiones, solapamientos y distancias. En el marco de este modelo de organización del campo visual, la posibilidad de interpretación deriva de la morfología y topología que resulta de la posición y distribución de elementos en un espacio dado, de las estructuras espaciales que conforman, de las relaciones de distancia que estos elementos establecen entre sí, de las acciones-fuerza ejercidas por las imágenes convertidas en vectores matemáticos. De este modo, la ordenación de la producción cultural de naturaleza visual se transforma en un problema de distribuciones espaciales, de estructuras topológicas y de reconfiguraciones morfológicas. Como ya advirtiera Warburg, pensar topológicamente –y no tipológicamente- el campo de las formas visuales elude planteamientos tendentes a la dicotomización, la binarización o el comparatismo simple, agregando complejidad.
Este modelo de reorganización de la producción cultural de naturaleza visual proporciona, pues, materiales interesantes para plantear versiones alternativas al eje cronotrópico de los regímenes ordenadores tradicionales, extendiendo, así, las posibilidades de un debate intelectual instalado hace tiempo en el pensamiento histórico-artístico, que ya ha hablado de transcronología (Warburg), anacronía (Didi-Humberman, Kubler) o heterocronía (Moxey). Como tal, el espacio topológico es también un espacio-tiempo, que integra la dimensión espacial –puntos en un espacio- y la temporal –vectores-fuerza actuando-. Como afirma Gabriela Sparza, el «tiempo topológico se expande, se contrae, se pliega, se riza, se acelera, se detiene, y enlaza otros tiempos y otros espacios»[4].
Estas configuraciones morfológicas y topológicas también cuestionan las categorías tradicionales de delimitación geográfica y geopolítica que constituyen la base del modelo nacional de historia del arte, ya ampliamente discutido –es cierto-, pero que son igualmente esenciales para el ya no tan nuevo paradigma de historia del arte transnacional y/o global, pues, si bien planteado este último como una superación del modelo nacional, también aquí los fenómenos histórico-artísticos están remitidos a unas coordenadas geográficas y geopolíticas, dado que es su ubicación relativa a una frontera lo que les confiere su entidad de fenómenos globales o transnacionales. En un grafo y en un espacio topológico no hay fronteras geopolíticas ni geográficas; lo que encontramos es un continuum espacial hecho de conexiones o grados de proximidad y/o distancia, tensiones en un campo de fuerzas. Todo ello nos conmina a explorar la transformación de las narrativas espaciales en narrativas topológicas.
Este espacio es, además, un espacio gradativo (escalar), porque la ubicación de los elementos no viene dada por atributos fijos que formen parte de la naturaleza ontológica invariable de los artefactos culturales, sino por valores de grado: la distancia entre las imágenes no habla de una diferencia ontológica-tipológica, sino de grados de mayor o menor similitud.
Es, finalmente, un espacio de alta dimensión. El lugar en el que habitan las imágenes digitales, en cuanto conjuntos de datos diversos y multivariables, constituye un espacio de naturaleza informacional conformado por la recombinación de múltiples características (features) que se articulan en un número ingente de dimensiones posibles (feature space). Por eso hablamos de un espacio de alta dimensión –high dimensional, n-dimensional, hyperspace-. Cada imagen –en cuanto objeto-entidad visual- es un punto en ese espacio de alta dimensión. Si bien es cierto que los algoritmos de reducción dimensional –como el utilizado en este proyecto- están diseñados para generar una representación de baja dimensión a fin de hacer inteligible a la cognición humana –que está acostumbrada a ver en tres dimensiones- un número extenso de características y dimensiones, lo cierto es que lo representado es información multidimensional. La exploración de las implicaciones que este tipo de espacio multidimensional y vectorial pueda comportar para la interpretación y el análisis cultural todavía se encuentra en un estadio inicial[5], sin embargo, parece claro que la exploración de sus potencialidades, en cuanto espacio alternativo a la noción de espacio físico-euclídeo y de espacio geográfico, se presenta de gran interés, pues abre una línea de investigación para abordar desde una aproximación topológica, física y geométrica el problema de cómo ordenar fenómenos complejos n-dimensionales, que se proyectan en múltiples posibilidades, que se transforman en escalas gradativas y que, por tanto, son irreducibles a los procesos de catalogación, categorización o clasificación propios de la lógica clásica, con su inexorable función delimitadora. Esta tensión entre la irreducibilidad de los fenómenos culturales complejos a ser clasificados en categorías estancas y la necesidad de establecer un orden que nos permita asir su complejidad ha sido una preocupación intelectual de la Historia del Arte y de los estudios culturales y visuales, en general, que puede ser acometida ahora con nuevos instrumentos de exploración y de pensamiento.
* Algunas de las reflexiones presentadas aquí se han tomado de Rodríguez Ortega, Nuria. «Artefactos, maquinarias y tecnologías ordenadoras. A propósito de los catálogos de arte», en Catálogos desencadenados. Málaga: Vicerrectorado de Cultura-Universidad de Málaga (en prensa), donde se desarrolla más ampliamente esta cuestión.
Cita recomendada: Rodríguez Ortega, Nuria. «Espacialidades otras. Breves consideraciones», en Barr X Inception CNN (dir. Nuria Rodríguez Ortega, 2020). Disponible en: http://barrxcnn.hdplus.es/espacialidades-otras/ [fecha de acceso].
[1] Carlos Miranda tiene mucho que decir sobre esto.
[2] Diferencias y similitudes entre el espacio vectorial producida por una CNN y los paneles de Warburg se analizan con más detalle en Rodríguez Ortega, Nuria. «Artefactos, maquinarias y tecnologías ordenadoras. A propósito de los catálogos de arte», en Catálogos desencadenados. Málaga: Vicerrectorado de Cultura-Universidad de Málaga (en prensa).
[3] Véase DRUCKER, Johanna. Graphesis. Visual Forms and Knowledge Production. Cambridge: Harvard University Press, 2012, p. 65.
[4] SPERANZA, Graziela. Cronografías. Arte y ficciones de un tiempo sin tiempo. Madrid: Anagrama, 2017.
[5] De hecho, frente a las estrategias de reducción de la dimensionalidad, también se están proponiendo otras alternativas, por ejemplo, SANDERSON, G. Thinking visually about higher dimensions. Disponible en: https://www.youtube.com/watch?v=zwAD6dRSVyl [consulta: 18-3-2020], quien establece una distinción entre ver y pensar visualmente. Aquí se abre otra vía de exploración interesante.